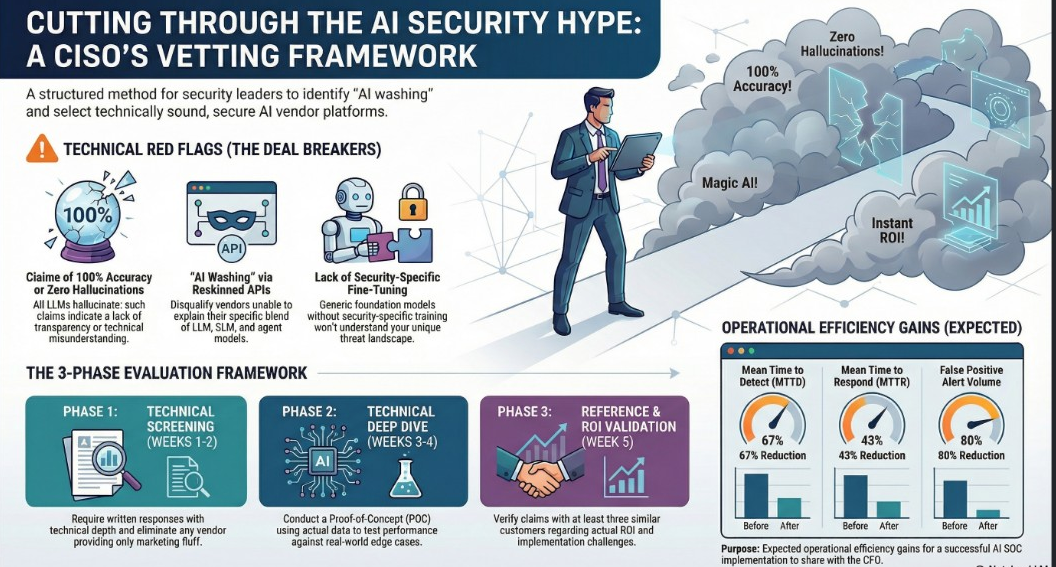
The AI company that made safety its entire identity just quietly deleted its most important promise.
Anthropic, creator of Claude and self-proclaimed leader in responsible AI development, has overhauled its flagship Responsible Scaling Policy (RSP)—and in the process, abandoned the central commitment that differentiated it from competitors like OpenAI and Google.
The change, revealed in a TIME Magazine exclusive, marks a turning point for the AI safety movement. If the company founded specifically to prioritize safety can’t maintain its principles, who can? [
CISO Marketplace | Cybersecurity Services, Deals & Resources for Security Leaders
The premier marketplace for CISOs and security professionals. Find penetration testing, compliance assessments, vCISO services, security tools, and exclusive deals from vetted cybersecurity vendors.
![]()
Cybersecurity Services, Deals & Resources for Security Leaders](https://cisomarketplace.com/blog/anthropic-claude-code-security-rattles-cybersecurity-markets)
What Anthropic Promised
When Anthropic introduced the RSP in 2023, it made a bold commitment: the company would never train an AI system unless it could guarantee in advance that safety measures were adequate.
This wasn’t marketing language. It was a binding operational constraint—a bright red line that would halt development if safety couldn’t be assured. Company leaders, including CEO Dario Amodei and chief science officer Jared Kaplan, repeatedly cited this promise as proof that Anthropic was different from the “move fast and break things” crowd.
The pledge served multiple purposes:
- Internally: It forced the company to build safety measures before capability, not after
- Externally: It positioned Anthropic as the responsible choice for enterprises and governments
- Industry-wide: Anthropic hoped it would pressure competitors to adopt similar constraints [
Claude Code Hit With Critical RCE Vulnerabilities: What Dev Teams Need to Know
Security researchers have disclosed three critical vulnerabilities in Claude Code, Anthropic’s AI-powered coding assistant. The flaws could allow attackers to execute arbitrary code on developers’ machines and steal API keys—all by simply getting a victim to clone a malicious repository. Check Point Software reported all three vulnerabilities to Anthropic,
![]()
Hacker Noob TipsHacker Noob Tips

What Changed
The new RSP, reviewed by TIME, scraps the guarantee-in-advance requirement entirely.
Instead, Anthropic now commits to:
- Being more “transparent” about safety risks
- “Matching or surpassing” competitors’ safety efforts
- “Delaying” development only if Anthropic considers itself the AI leader AND believes catastrophe risks are significant
Notice the shift. The old policy was a categorical constraint: don’t train without safety guarantees. The new policy is relative and conditional: do at least as well as competitors, and maybe slow down if we’re winning and things look bad.
The Rationale
Kaplan’s explanation to TIME was remarkably candid:
“We felt that it wouldn’t actually help anyone for us to stop training AI models. We didn’t really feel, with the rapid advance of AI, that it made sense for us to make unilateral commitments… if competitors are blazing ahead.”
Translation: if everyone else is racing, we can’t afford to walk.
The company points to several factors:
- No federal regulation materialized: Anthropic had hoped the RSP would become a blueprint for binding laws. Instead, the Trump Administration has endorsed a “let-it-rip” approach
- Global governance failed: International AI treaties that seemed possible in 2023 are now clearly dead
- Competition intensified: The race for AI supremacy—between companies and nations—has only accelerated
- Safety science proved harder: What looked like bright red lines turned out to be “fuzzy gradients”
The “Frog-Boiling” Risk
Chris Painter, policy director at METR (a nonprofit focused on AI safety evaluations), reviewed an early draft of the new policy. His assessment is sobering:
“This is more evidence that society is not prepared for the potential catastrophic risks posed by AI.”
Painter warned of a “frog-boiling” effect under the new approach. Without binary thresholds that could trigger development pauses, danger can ramp up gradually without any single moment that sets off alarms.
The old RSP’s strength was its simplicity: certain capabilities meant stop. The new RSP requires continuous judgment calls about relative risk levels—exactly the kind of assessment that’s easy to rationalize away under competitive pressure. [
Anthropic’s Week From Hell: Pentagon Threats, Abandoned Safety Pledges, and Critical Vulnerabilities
In the span of just five days, Anthropic—the AI company that built its entire brand on being the “responsible” alternative to OpenAI—has watched its carefully constructed safety narrative collapse. The company faces a Pentagon ultimatum over its $200 million defense contract. It quietly scrapped its flagship safety pledge.
![]()
Breached CompanyBreached Company

The Irony
Anthropic was founded in 2021 by Dario Amodei, his sister Daniela, and other former OpenAI employees who left specifically because they felt OpenAI wasn’t taking AI safety seriously enough.
Their founding thesis: to do proper AI safety research, you have to build frontier models—even if that accelerates the dangers you fear. The RSP was supposed to square this circle by ensuring safety kept pace with capability.
Now the company admits that market dynamics override safety constraints. If competitors advance regardless, unilateral restraint “wouldn’t help anyone.”
But that logic applies universally. If every company uses it, nobody pauses. The race continues. And the safety research that justified building dangerous capabilities in the first place becomes secondary to competitive positioning.
What This Means for Enterprises
If you’ve chosen Claude partly because of Anthropic’s safety reputation, this development demands attention.
Reassess your vendor assumptions. Anthropic’s RSP was a differentiator. With that constraint removed, the gap between Anthropic and competitors narrows. Safety commitments that exist today may not survive tomorrow’s market pressure.
Don’t rely on vendor self-regulation. The RSP change shows that even companies founded on safety principles will modify those principles under competitive pressure. Build your own evaluation frameworks rather than trusting vendor promises.
Watch for downstream effects. If Anthropic—the industry’s safety anchor—is loosening constraints, expect others to follow. The “responsible AI” category may be heading for a race to the bottom.
The Bigger Picture
Google’s “don’t be evil” became a punchline when they dropped it. Anthropic’s safety pledge may be heading the same direction.
The difference is speed. Google took years to quietly abandon its motto. Anthropic went from “we won’t train without safety guarantees” to “we can’t make unilateral commitments” in under three years.
Kaplan insists this isn’t a U-turn: “If all of our competitors are transparently doing the right thing when it comes to catastrophic risk, we are committed to doing as well or better.”
But “as well as competitors” is a very different standard than “guaranteed adequate safety measures.” One is a floor set by the industry’s least cautious players. The other was a ceiling set by Anthropic’s own principles.
The ceiling is gone. Now we find out how low the floor can go.
Sources
- TIME Magazine: Exclusive: Anthropic Drops Flagship Safety Pledge